Hi, I am Umar H., and let me take you on a little journey. Imagine, it is 2015, and I am managing a project for a client who had terabytes of data scattered across different departments. Their data was like an untamed beast – unstructured, unmanaged, and frankly, overwhelming.
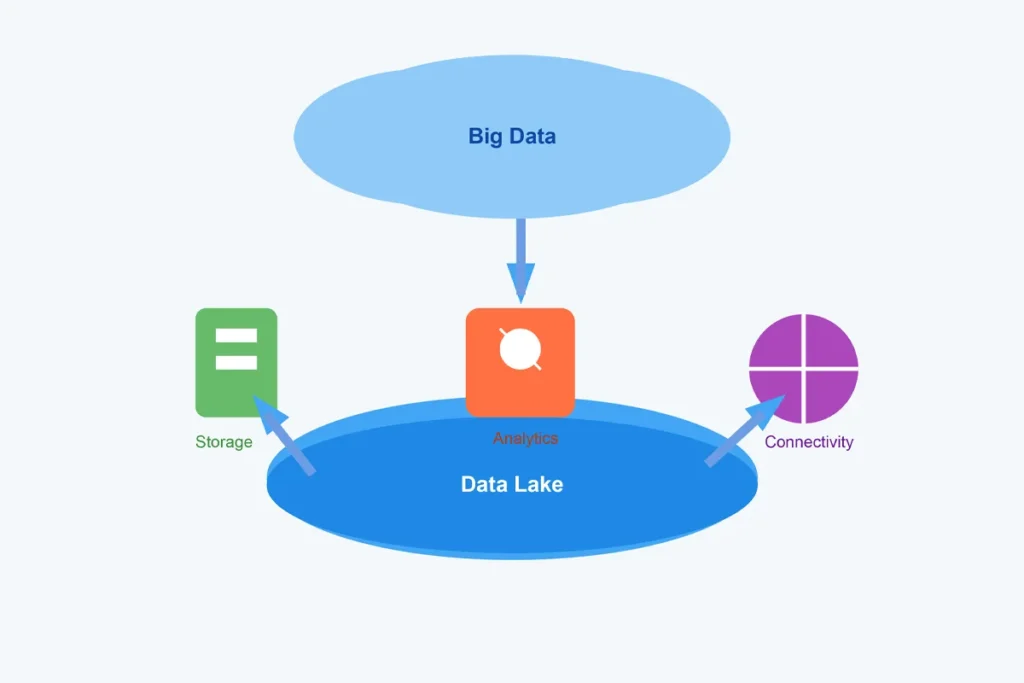
★ Enter the “Data Lake.”
The idea was simple, gather all that data, structure it when needed, and make it accessible for analysis. Now, if you’re wondering how Big Data and Data Lake work together and why they’re essential, remain with me. I will guide you step by step.
What Is Big Data? 📊
Think of Big Data as a digital tsunami – endless waves of information generated every second. From your social media posts to e-commerce transactions and even IoT sensors, we are creating 2.5 quintillion bytes of data daily.
Key Characteristics of Big Data
Big Data is defined by these “3 Vs”:
- Volume: Massive amounts of data (think petabytes or exabytes).
- Velocity: The speed at which data is generated and processed.
- Variety: Structured, semi-structured, and unstructured data.
Why Does Big Data Matter?
Big Data powers everything from personalized Netflix recommendations to global climate models. Businesses leverage it for:
- Customer insights✓
- Operational efficiencies✓
- Market predictions✓
What Is a Data Lake? 🌊
Imagine a vast reservoir of water. That’s your Data Lake, except instead of water, it holds raw, unfiltered data. Unlike traditional databases, which need data pre-processed and structured, a data lake can store everything as-is.
Data Lake Example: How It Works
Here’s a simple scenario:
- Source: A retail business collects data from POS systems, online orders, and customer feedback.
- Storage: All this data—structured (sales data) and unstructured (social media reviews)—flows into a data lake.
- Usage: Data scientists analyze it for trends, marketing tweaks, and inventory optimization.
Explore how AWS manages data lakes. What is cloud based data platform?
What are the features of Data Lake🔎
Data lakes come with a range of features that make them indispensable for modern data strategies. Let’s break them down:
1. Scalability
A data lake can grow to accommodate vast amounts of data, making it ideal for organizations that deal with ever-expanding datasets.
2. Flexibility
Unlike traditional databases, a data lake accepts data in all forms: structured, semi-structured, and unstructured.
3. Cost-Efficiency ✅
Data lakes often use affordable storage solutions, such as cloud services, reducing the overall cost of managing data.
4. Advanced Analytics Support
With tools like Apache Spark and TensorFlow, data lakes enable advanced analytics, including machine learning and real-time data processing.
5. Metadata Management 🔖
Metadata tagging ensures that data remains organized and easily searchable, which is crucial for efficient data retrieval.
6. Data Security and Compliance
Modern data lakes incorporate encryption and access control measures, ensuring that sensitive data remains secure and compliant with regulations.
Big Data and Data Lake: The Perfect Partnership 📚
When Big Data meets a Data Lake, it’s like coffee meeting cream—a perfect blend.
Why They Complement Each Other:
- Big Data needs storage: And a data lake provides that.
- Unstructured data: Data lakes shine with raw, unstructured data, a staple of Big Data.
- Scalability: Handling growing volumes of data is a breeze.
Data Lake vs Big Data: Are They the Same?
Nope! Here’s the difference:
| Feature | Big Data | Data Lake |
| Definition | Huge data sets | A storage system |
| Role | Data source | Data storage and processing |
| Examples | Social media, IoT | AWS S3, Azure Data Lake |
Advantages of Using Data Lakes ✅
Data lakes offer numerous benefits that can transform the way businesses handle their data:
1. Scalability
Data lakes can scale to accommodate petabytes of data, whether structured or unstructured, without compromising performance.
2. Cost Efficiency
Storing raw data in a lake is significantly cheaper compared to traditional data warehouses. Many platforms, such as AWS S3, offer pay-as-you-go models.
3. Flexibility
Unlike structured systems, data lakes allow for storage of any type of data—from spreadsheets to multimedia files.
4. Faster Insights
With tools like Apache Spark, businesses can process large datasets quickly, enabling real-time decision-making.
5. Democratized Access
Data lakes make it easier for various teams—from analysts to engineers—to access and analyze data, fostering collaboration and innovation.
6. Future-Ready
As organizations embrace AI and machine learning, data lakes provide the foundation for training advanced models.
Read more about the benefits of data lakes.
Big Data Explained
Big Data refers to massive and complex datasets that cannot be managed or processed using traditional data management tools. Its importance lies in its potential to uncover patterns, trends, and insights that would otherwise remain hidden. For example, analyzing customer behavior on e-commerce platforms can help businesses personalize shopping experiences.
Key Characteristics of Big Data
Big Data is defined by these “3 Vs”:
- Volume: Massive amounts of data (think petabytes or exabytes).
- Velocity: The speed at which data is generated and processed.
- Variety: Structured, semi-structured, and unstructured data.
Why Does Big Data Matter?
Big Data powers everything from personalized Netflix recommendations to global climate models. Businesses leverage it for:
- Customer insights✓
- Operational efficiencies✓
- Market predictions✓
Data Lakes vs. Data Warehouses: Key Differences 🎮
Both data lakes and data warehouses play essential roles in data management, but they serve different purposes. Let’s break it down:
Definition
- Data Lake: A centralized repository for storing raw, unstructured, and structured data.
- Data Warehouse: A structured storage solution designed for specific, processed data.
Storage and Structure
- Data Lake: Stores everything as-is, with no predefined schema. Think of it as a “dump everything here” approach.
- Data Warehouse: Organizes data into schemas, tables, and rows, ensuring it’s clean and ready for queries.
Processing Style
- Data Lake: Ideal for big data analytics and real-time data processing.
- Data Warehouse: Best for historical data analysis and business intelligence.
Cost ✅
- Data Lake: More cost-effective due to its scalable architecture.
- Data Warehouse: Higher costs due to structured storage and processing needs.
Use Cases
| Feature | Data Lake | Data Warehouse |
| Type of Data | Raw, unstructured, structured | Structured, processed |
| Analysis | Real-time, exploratory | Business intelligence, reporting |
| Examples | AI, machine learning | KPI dashboards, financial reporting |
When to Use Each
If you are wondering whether to use a data lake or a data warehouse, think about your specific needs. Let’s break it down with a storytelling twist.
💡 Imagine you are running a business. You are collecting endless streams of raw, unstructured data from social media, IoT devices, and online transactions. Your goal? Extract insights without worrying about structuring data upfront. That’s where a data lake shines! 🌊
Now, suppose you are managing a reporting-heavy operation where data needs to be structured and easily accessible for business intelligence tools. In this case, a data warehouse is your best companion. 📊
Key Scenarios for Data Lakes
- Unstructured Data Storage:
- Use a data lake when you need to store diverse data types like videos, images, logs, and raw text.
- Example: A media company storing high-resolution videos for analysis.
- Data Science Projects:
- Ideal for experimenting with machine learning algorithms and predictive analytics.
- Example: Retail businesses predicting sales trends using raw transaction logs.
- Cost-Effective Storage:
- If you’re dealing with massive data volumes, data lakes are generally cheaper.
- Example: Startups storing years of IoT sensor data for future analysis.
Key Scenarios for Data Warehouses
- Structured Reporting:
- Perfect for generating business intelligence reports.
- Example: A financial firm generating monthly revenue dashboards.
- Low-Latency Queries:
- Use when quick queries on structured data are critical.
- Example: Healthcare providers querying patient records for urgent care.
- Compliance and Governance:
- For industries needing strict data regulation, warehouses are easier to control.
- Example: Banking institutions maintaining transaction records for audits.
A Quick Comparison Table 📝
| Criteria | Data Lake 🌊 | Data Warehouse 📊 |
| Type of Data | Unstructured, semi-structured | Structured |
| Use Case | Raw data storage, ML projects | BI reporting, analytics |
| Cost | Cheaper for storage | Higher due to preprocessing |
| Performance | Slower for analytics | Faster for structured queries |
| Scalability | Highly scalable | Limited scalability |
Pro Tip: Combine both for a modern data architecture. Use a data lake for storage and experimentation, and migrate relevant data to a warehouse for structured analysis. ✅
Implementing Data Lakes in Business:
Use Cases and Applications
Data lakes have become a powerful tool for businesses to manage vast amounts of raw data in its native format. Unlike traditional databases that require data to be processed and structured, data lakes can store unstructured, semi-structured, and structured data, making them ideal for businesses dealing with large and diverse datasets.
Use cases for data lakes include customer analytics, where businesses can store a variety of data such as social media interactions, website visits, and purchase history to gain comprehensive insights into customer behavior. Additionally, data lakes are used in the healthcare sector to store patient records, medical images, and research data for advanced analytics and machine learning applications. Financial institutions also use data lakes to manage transaction data, market trends, and customer information, enabling real-time fraud detection and predictive analytics.
These versatile applications show the growing importance of data lakes in driving data-driven decision-making across industries.
Best Practices for Implementation
Successfully implementing a data lake requires careful planning and a structured approach. One of the best practices is to define clear goals and objectives for what the data lake is intended to achieve. This could include improving decision-making, enhancing data security, or supporting machine learning models. It’s also crucial to establish a robust data governance framework to ensure data quality, security, and compliance.
Organizations should employ metadata management strategies to make sure data can be easily searched, accessed, and understood. Another key practice is to start small with a pilot project, which allows businesses to test the data lake’s effectiveness and identify potential issues before scaling it. Additionally, leveraging cloud-based solutions can help businesses minimize infrastructure costs while enabling flexible scalability as data needs grow.
Common Issues with Data Lakes
While data lakes offer numerous benefits, there are several challenges businesses face when implementing them. One of the most common issues is the risk of data becoming a “data swamp,” where it is disorganized and difficult to access or analyze. This can happen when proper data governance practices, such as labeling and cataloging data, are not followed.
Another challenge is ensuring data security and privacy, as large amounts of sensitive data can make organizations vulnerable to data breaches and compliance violations. Businesses also face difficulties with data integration, especially when dealing with diverse data sources and formats. Furthermore, maintaining the performance of a data lake as it grows can be challenging, particularly when dealing with large volumes of real-time data.
Solutions to Overcome Challenges
To overcome the challenges of data lakes, businesses can adopt several strategies. Implementing a strong data governance framework from the start is essential to prevent data from becoming unmanageable. This includes creating clear data management policies, utilizing metadata to catalog data, and ensuring that data is well-organized and searchable. For security and privacy, businesses should incorporate encryption and access controls, along with regular audits to ensure compliance with data protection regulations.
To handle data integration, businesses can use data integration tools and platforms that support various data formats and sources, making it easier to centralize data. Moreover, implementing data lake optimization techniques, such as partitioning and indexing, can help improve performance and ensure that the system can handle increasing data volumes without slowing down. By addressing these issues, businesses can fully realize the potential of their data lakes and use them to drive actionable insights.
Conclusion
In conclusion, big data and data lakes are transforming how businesses store, manage, and analyze vast amounts of information. Data lakes, with their ability to handle unstructured, semi-structured, and structured data, provide a flexible and scalable solution for organizations looking to gain insights from diverse data sources. While there are challenges in implementing and managing data lakes, such as data governance, security, and integration issues, adopting best practices and robust frameworks can help businesses overcome these hurdles. By harnessing the power of big data and data lakes, companies can unlock new opportunities for innovation, operational efficiency, and data-driven decision-making, positioning themselves for success in the digital age.
FAQs
Big data refers to the large volume of data that is generated at a high velocity, in various formats, and from numerous sources. A data lake, on the other hand, is a centralized repository that stores all types of data—structured, semi-structured, and unstructured—allowing businesses to analyze and derive insights from diverse data sources.
Data lakes offer several benefits to businesses, including the ability to store and analyze large amounts of diverse data, scalability for growing data needs, and cost-effective solutions, especially when integrated with cloud technologies. They also support advanced analytics, machine learning, and AI, enabling better decision-making and insights.
The primary challenges of implementing data lakes include data governance issues (such as maintaining data quality and organization), security risks, managing data integration from multiple sources, and ensuring the system’s performance as it scales. These issues can be mitigated with proper planning, robust data management strategies, and security protocols.
To ensure security, businesses should employ strong encryption, access controls, and regular audits to protect sensitive data. They should also implement identity management solutions and ensure compliance with relevant data protection regulations such as GDPR or HIPAA.
Yes, data lakes can handle real-time data processing, particularly when integrated with advanced technologies like stream processing and real-time analytics tools. This makes data lakes ideal for applications such as fraud detection, real-time customer insights, and other use cases that require immediate analysis of incoming data.